N-gram
比較「機器生成出來的翻譯」和「人工翻譯的結果」最直接的方法,肯定是逐字拿來比較對吧。以下會先用n-grams的概念,讓大家有初步的了解後, 再說明為什麼n-gram的方法不好,接著介紹BLEU。
Example 1:
Candidate: the cat the cat on the mat.
R1: the cat is on the mat.
R2: there is a cat on the mat.一開始的評估方式:用precision。
只需要考慮Candidate的情況即可,只要Candidate中的字有在Reference出現過,我們都會納入計算。
Exmple 1 (1-gram)
→ 7 / 7 = 1.0Exmple 1 (2-gram)
→ 5 / 6 = 0.8883

Example 2:
Candidate: the the the the the the the the.
R1: The cat is on the mat.
R2: There is a cat on the mat.Exmple 2 (1-gram)
= 8 / 8 = 1.0Example 2 (2-gram)
= 0 / 7 = 0

如果用上面的方法,來做計算的話,可以發現怎麼precision都超高,代表這個計算方法對自己太過有自信,但實際上卻不是這樣。因此,「Clipped count」就此產生。
Clipped Count
Clipped Count和Precision最大的差別是,原本Precision在計算是,只要有單字曾出現在Reference都會被納入計算,假設Reference只有一個the 但是Candidate缺有3個the ,容易被過度計算,因此Clipped Count改良了Precision,會考慮到Reference中「實際出現的次數」。

從剛剛提到Example 1, Example 2來舉例。
Example 1 (1-gram + clipped count)
→ 5 / 7 = 0.714Example 1 (2-gram + clipped count)
→ 3 / 6 = 0.5
Example 2(1-gram + clipped count)
→ 2 / 8= 0.25Example 2 (2-gram + clipped count)
→ 0/ 7= 0
講了這麼久,Clipped Count好像才比Precision好了那麼一點點。
現在終於可以上主菜來介紹BLEU了
懲罰因子(Brevity Penalty Factor)
先別急,再正式介紹BLEU之前,先來說說「懲罰因子」的故事。一般機器在翻譯的時候,很容易會比reference的句子還要長,這是因為機器無法像人類一樣很用很精簡的話語翻譯,而前面使用n-gram precision已經對這方面有所懲罰,但還不夠。
因為n-gram的匹配度可能會因為句子的長短而變好或變好,可能機器只有翻譯出部分的且精確的句子,其他就亂塞單字,其實這句的匹配度也能也很高。為了解決評分偏誤的問題,BLEU引入了Brevity Penalty Factor.
有了這個「brevity penalty factor」,那些「候選機率高機器翻譯的句子」必須在文句的長度、單字的選擇、單字的順序,都要考量到Reference的句子。
c: Candidate translation 的長度
r: Reference corpus的長度
「機器產生的翻譯」長度 > 「Reference」 → 不用給penalty,不懲罰。
「機器產生的翻譯」長度 <「Reference」 → 給 penalty,懲罰。
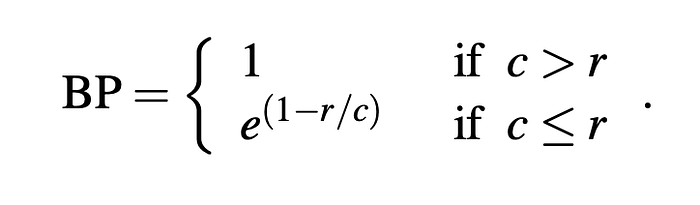
BLEU公式
由於n-gram的precision會隨著n數量的增加,而呈現指數遞減,為了平衡n之間的差異,使用了幾何平均值並加權,再乘上「懲罰因子」,得到下方的公式。

BLEU的原型系統採用「均勻加權」,Wn = 1 / N。N的上限為4,也就是最多只取4-gram。
趕緊拿範例來用用看:
機器翻譯:Going to play basketball this afteroon?
人工翻譯:Going to play basketball in the afternoon?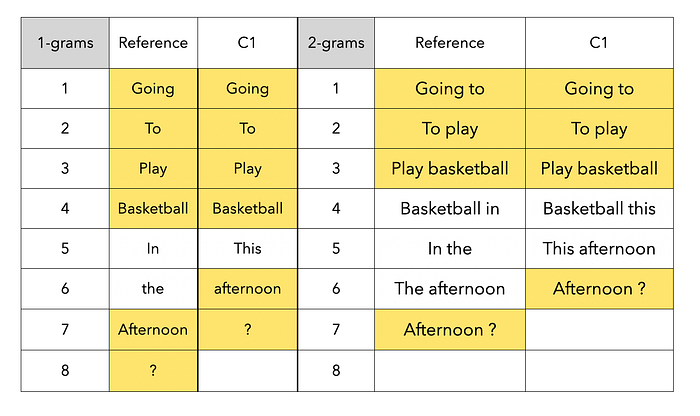
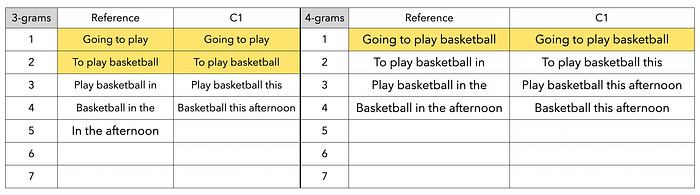
- 1-gram分數:P1 = 6 / 7 (Clipped Count)
- 2-gram分數:P2 = 4 / 6 (Clipped Count)
- 3-gram分數:P3 = 2 / 5 (Clipped Count)
- 4-gram分數:P4 = 1 / 4 (Clipped Count)
- BP = exp(1 — 8 / 7) = 0.8668
- BLEU = BP * exp( ( log(P1) + log(P2) + log(P3) + log(P4) ) / 4) = 0.4238
看到這邊可能會有一個疑問是,0.4238的效果到底是好還是不好,
BLEU的評估方法,區間從0到1。機器翻譯和Reference完全相同分數為1,完全不同為0。
BLEU的方法,也有些要注意的部分:
BLEU的分數會因為reference的多寡而影響他們的分數,每個句子有越多參考的reference,分數就會越高。論文中提到的一個例子是,500個test corpus,一個翻譯人員給每一句四個reference,可以得到0.348,若給兩個reference,得到0.2571。
差異也可以參考範例裡面多個句子之間的BLEU。
簡略敘述一下那個範例,用兩句Candidate和兩句Reference後,BLEU的分數得到0.793的分數。
結論
BLEU的好處是透過平均每一句的錯誤使得這樣的判斷結果和人類判斷的結果很類似。另外,BLEU目前常使用於「摘要評估」和「語言理解評估」等領域。
Reference:
